 3.1k+
作者:数据多鱼
2023-01-19 10:24:21 发布
3.1k+
作者:数据多鱼
2023-01-19 10:24:21 发布
为了找到满足您需求的最佳数据模型,通常使用一些技巧来进行分析,并根据该分析做出数据模型决策。本文将讨论一些建模技巧,并重构模型。
在建模前,首先要知道业务场景对数据提出的各种问题,而写出查询是确定数据模型结构的好方法。如果您知道查询需要在特定日期范围内返回结果,则应确保该日期不是节点上的属性,而是存储为单独的节点或关系。相反,对于大学课程而言,想找到与当前课程相似的课程产品,可以由课程上层类别入手,使搜索结果的所有课程更为有效。
即使您还不知道确切的查询语法,了解正在构建的系统或应用程序,围绕业务需求构建模型都将帮助您以更准确的方式设计。
为每个查询或功能找到理想的模型非常困难,正如我们在之前几篇文章中所讨论的那样,在选择模型时,需要权衡取舍。尽管您可能会改进某些方面,但无法获得一种万能的解决方案。
相反,您应该确定哪种模型最适合您的需求。您可能无法最大程度地发挥每个查询的性能,但是您可以通过某些资源、时间和代码来充分利用系统。
为此,您需要确定哪些查询必须绝对具有最佳性能,以及哪些功能对于提供价值至关重要。这可能是一个艰难的决定,Neo4j更具价值的是,数据模型具有灵活性,并且能够根据您的优先级随时间变化而更改。
我们可能会遇到在设计阶段未意识到的方案,找到这些的最佳方法之一是实际测试模型。
导入部分数据并在系统上执行测试和查询,这将确定您查询的结果是否适合您的需求或预期的性能。同样,Neo4j非常灵活,因此您可以调整模型或优化查询以优化输出。
在选择一个或多个模型时遇到困难?尝试为每个模型以及两者一起创建概念验证测试,并查看它们如何工作。什么是复杂的,什么不值得解决?是否有一种在现实生活中实际表现更好的方法,或者是多数据模型方法确实能为您带来最佳结果?有时,找出答案的最佳方法是使用实真实数据对其进行测试。
如上所述,Neo4j 模型始终可以进行更改。因此,数据模型具有一定的灵活性,并且易于调整,业务需求和优先级往往会波动,用户还可能改变其行为并引起业务变化。
Cypher 允许编写查询,执行批量更新、添加或删除属性,以及在结构中插入其他节点和关系。还提供了APOC标准库来帮助批处理查询和执行对集群实例的更新。
数据集的大小也会影响查询和性能。如果您的数据集较小,那么在更复杂的查询中可能看不到太多的性能影响。只有当数据量增加时,您才可能看到增加的影响。在这里,数据模型和查询优化对于最大化系统价值至关重要。
机场数据集
在本文中,我们将继续使用机场数据集,其中包含2008年1月美国各机场之间的连接。我们将数据存储在CSV文件中,这是将要导入到其中的图模型:
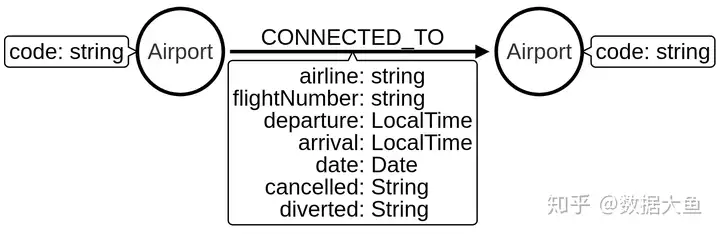
在导入任何数据之前,我们将在Airport标签和code属性上创建唯一约束,以确保我们不会意外导入重复的机场。以下Cypher 创建此约束:
CREATE CONSTRAINT ON (airport:Airport)
ASSERT airport.code IS UNIQUE
package cc.crrcgc.ccp;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.config.server.EnableConfigServer;
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}转载自知乎









